Cutting AI Costs Without Cutting Quality
AI API costs can spiral quickly. A simple chatbot hitting GPT-4o for every request can easily burn through hundreds of dollars a day. But most requests don't need the most expensive model. Here's how to optimize your spend without sacrificing response quality.
The Problem: One Model for Everything
Most developers start with a single model — usually GPT-4o or Claude Sonnet. It works well, but it's expensive for simple tasks like:
- Formatting text
- Answering FAQ-style questions
- Classifying content
- Simple translations
These tasks can be handled by smaller, cheaper models at 10-50x lower cost with comparable quality.
Strategy 1: Intelligent Routing
RoutePlex's routeplex-ai model automatically selects the best model for each request based on complexity:
from openai import OpenAI
client = OpenAI(
base_url="https://api.routeplex.com/v1",
api_key="rp_live_your_key"
)
# Simple question → routes to cheaper model
response = client.chat.completions.create(
model="routeplex-ai",
messages=[{"role": "user", "content": "What is the capital of France?"}],
extra_headers={"X-RoutePlex-Strategy": "cost"} # Optimize for cost
)With the cost strategy, simple requests route to efficient models like GPT-4o Mini or Gemini Flash, while complex reasoning tasks still get premium models.
Strategy 2: Pre-Request Cost Estimation
Before sending an expensive request, check what it will cost:
import requests
headers = {"Authorization": "Bearer rp_live_your_key"}
# Use the free estimate endpoint before sending
estimate = requests.post(
"https://api.routeplex.com/api/v1/chat/estimate",
headers=headers,
json={
"messages": [{"role": "user", "content": long_document}],
"mode": "manual",
"model": "gpt-4o"
}
).json()
estimated_cost = estimate["data"]["estimated_cost_usd"]
if estimated_cost > 0.10: # More than 10 cents
# Use a cheaper model instead
model = "gpt-4o-mini"The estimate endpoint is free and doesn't count toward your usage.
Strategy 3: Budget Controls
Set daily and monthly spending caps in your dashboard to prevent runaway costs:
- Daily token cap — Maximum tokens per 24-hour period
- Daily cost limit — Hard stop on daily spend
- Monthly soft cap — Warning when approaching your budget
When a limit is reached, requests return a clear error code so your application can handle it gracefully.
Strategy 4: Use the Right Model Size
Here's a rough guide for model selection by task:
| Task Type | Recommended | Cost Level |
|---|---|---|
| Simple Q&A, formatting | GPT-4o Mini, Gemini Flash | $ |
| General conversation | GPT-4o, Claude Sonnet 4 | $$ |
| Complex reasoning | o3, Claude Opus 4 | $$$ |
| Code generation | Claude Sonnet 4, GPT-4.1 | $$ |
Or let routeplex-ai decide automatically based on your chosen strategy.
Real-World Impact
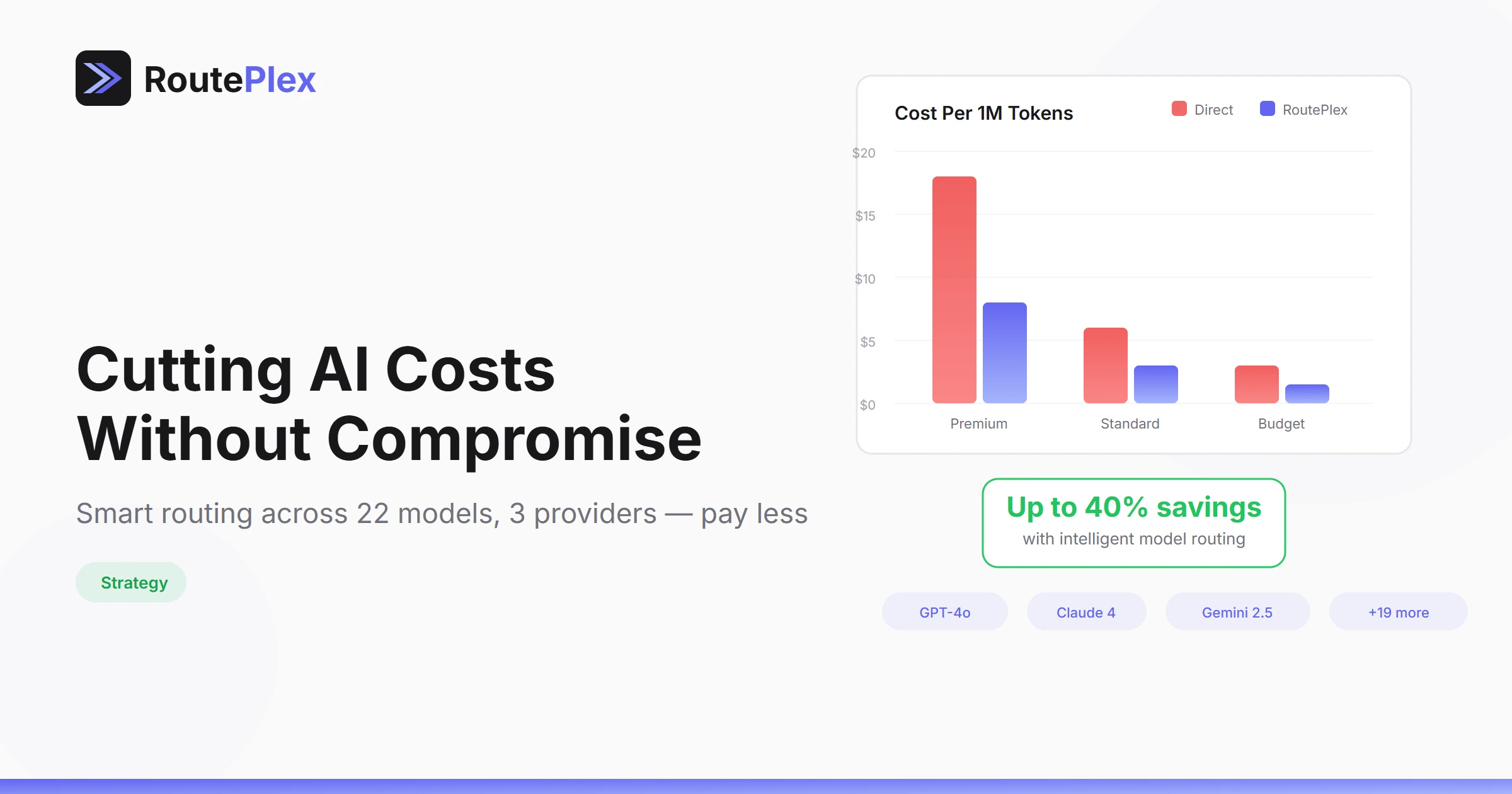
Teams using RoutePlex's cost strategy typically see 40-60% cost reduction compared to routing everything through a single premium model, with minimal quality difference for most use cases.
The key insight: not every request needs the most powerful model. Intelligent routing makes this optimization automatic.